L'implemetazione della tecnologia Hyper-Threading nei Pentium 4 risale alla prima comparsa del core Northwood, ma l'attivazione di tale modalità di utilizzo della CPU appartiene ai processori con velocità di clock uguale e superiore ai 3.06 GHz.
A detta dell'Intel, l'aumento di prestazioni delle nuove CPU con tecnologia H.T. risulta pari al 30%; Com'è possibile? L'attivazione dell'H.T. è così potente?
Per rispondere a queste domande, dobbiamo parlare dell'architettura Netburst delle CPU Pentium 4 (v. figura 10). Le pipeline del Pentium IV sono costituite da 20 stadi, e formano il ciclo "fetch-decode-execute." I primi 5 stadi caricano le istruzioni, e le decodificano (In-order front end). I successivi sette stadi si occupano dell'organizzazione delle istruzioni decodificate, e dell'invio di quest'ultime alle unità d'esecuzione (out-of order execution logic). I cinque stati successivi costituiscono la fase d'esecuzione vera e propria, e coinvolgono le unità di calcolo (fase d'esecuzione). Infine, gli ultimi stadi riordinano i risultati per il calcolo delle nuove istruzioni (retirement).
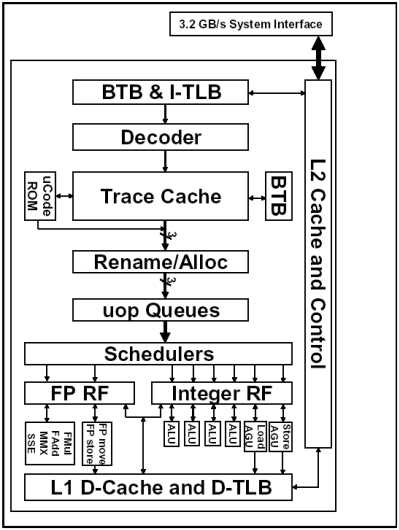
FIGURA 10.
(L'architettura Netburst del Pentium IV).
Il "in order front end" del PIV è formato da diverse unità, e precisamente: l'IA-32 Instruction TLB, il front end Branch predictor (BTB), l' IA-32 Instruction Decoder, la Trace Cache, e il Microcode ROM. All'interno di questi elementi avviene la ricerca, il caricamento, e la decodifica delle istruzioni in micro-istruzioni (ogni istruzione è tradotta in una o più istruzioni RISC a lunghezza fissata dette micro-istruzioni). l'out-of-order Execution logic contiene: l'Allocator, il Register Rename, l'uop Queues, e lo Schedulers; In questa fase avviene l'allocazione delle risorse, e l'organizzazione delle istruzioni decodificate (micro-istruzioni) per l'invio alle unità di esecuzione; La fase d'esecuzione vera e propria comprende le unità di calcolo. Di queste fanno parte: le unità di calcolo ALU (per l'elaborazione delle operazioni a calcolo intero), e le unità di calcolo in virgola mobile (FPU). Infine nella fase di "retirement" i risultati delle micro-istruzioni vengono restituiti ai registri appropriati per l'esecuzione del programma, o in alcuni casi, alle fasi precedenti delle pipeline.
Menu Sezione/Pagina Precedente/Pagina Successiva/Torna alla Homepage
Sito:megaoverclock.supereva.it